

Hogyan működik az SQL optimalizálás?
Amennyiben nem vagyunk elégedettek a lekérdezéseink sebességével 3 módon tehetjük hatékonyabbá azt:- Módosítjuk az indexeinket vagy újakat hozunk létre. Ez a legegyszerűbb és a leggyorsabb módja az optimalizálásnak, mivel így kódszinten a szoftverünkhöz nem kell nyúlni.
- Módosítjuk a lekérdezés struktúráját. Ez alatt azt értjük például, hogy meg kell változtatnunk a JOIN típusát vagy több feltételt kell írnunk még a query-be. Ekkor már módosítanunk kell kód szinten is, így ez a folyamat már hosszadalmasabb az előzőnél.
- Módosítjuk az adatok szerkezetét. Azaz új táblát kell létrehoznunk vagy oszlopokat kell áthelyeznünk egyik táblából a másikba. Ez a folyamat a legköltségesebb, gyakorlatilag teljes refaktorálást jelent kódszinten.
MySQL ismeretek felfrissítése
Mielőtt tárgyalnánk az optimalizálást, nem árt felfrissítenünk a MySQL tudásunkat. Alaposan tisztában kell lennünk, hogyan működik az adatbázis, mielőtt optimalizálásba kezdünk.Miért és hogyan használjuk az indexelést?
Indexelést természetesen a sebesség növelése érdekében használunk. Ha felindexelünk egy oszlopot, akkor az adatbázis rendszer készít általában egy B-Tree-t vagy hasító táblát (hash table) az adott oszlophoz, aminek segítségével anélkül éri el a keresett adatokat, hogy végig kellene szkennelni az összes rekordot. Így nagyon hatékonnyá tudjuk tenni az olvasási műveleteket, viszont a módosítási műveletek lassulnak, mivel nem csak az adott rekordot kell módosítani, hanem a letárolt indexeket is, az új rekordnak megfelelően, ezt automatikusan végzi a rendszer. Ez a magyarázat arra is, hogy ha gyors lekérdezéseket szeretnénk, akkor miért nem indexeljük fel az összes oszlopot. Meg kell találni az ideális egyensúlyt az indexelt és nem indexelt mezők között. Általában a WHERE-ben megadott oszlopokon érdemes lennie indexeknek.Index Típusok
- KEY vagy INDEX: a normál index, amit beállíthatunk bármilyen oszlopra. Ez a típus semmilyen adat megkötéssel nem jár. Használható nem egyedi értékekre is.
- UNIQUE: azaz egyedi index. A neve is enged arra következtetni, hogy olyan oszlopokra használhatjuk, amelyekben egyedi vagy NULL értékek lesznek. Ez a típus már adatmegszorításokkal jár. Azaz nem szúrhatunk be olyan rekordot, amelynek mezője unique indexszel van ellátva és olyan értékű mező már létezik a táblában. A NULL bár engedélyezett, de nem ajánlott, mivel a sok NULL érték rontja az indexelést.
- PRIMARY: hasonló a unique indexhez, csak itt a legfontosabb, hogy nem vehet fel NULL értéket. Gyakorlatilag ez a mező egyértelműen beazonosít egy rekordot a táblában. Minden rekord primary mezőjének kötelezően különbözőnek kell lennie, ezért ez a leghatékonyabb index. A legtöbb adatbázismotor fizikai adattárolón, fájlokban tárolja a rekordokat, amit primary index szerint sorban tárol. Ennek a következménye, hogy alapértelmezetten egy lekérdezésben, ha nem szerepel ORDER BY rendezési parancs, akkor mindig primary index szerint növekvő sorban fogjuk megkapni a rekordokat.
- FULLTEXT: a neve is árulkodik, hogy szöveges mezők indexelésére használható, igazából kizárólag csak azokra. Az index implementálása is különbözik az összes többitől, mert ez nem valósítható meg sem B-Tree-vel, sem hasító táblával. Amennyiben ezt az indextípust alkalmazzuk, úgy eltérő szintaktikájú lekérdezést kell használnunk, különben az adatbázismotor nem tudja használni az indexet, a későbbiekben látni fogunk erre példát. MATCH() / AGAINST()
Helyes mezőtípus választás
Érdemes alaposan átgondolva megválasztanunk egy adott tábla mezőinek típusát, mivel ezt a későbbiekben, ha már sok fejlesztés épül rá, egyre több munkával jár megváltoztatni. A mezők típusa fogja megadni azt, hogy az adatbázis motor mekkora helyet tartson fent az adott érték tárolásához. Természetesen annál hatékonyabb az író és olvasó műveletek sebessége minél kisebbek ezek az értékek. Értelemszerűen minél kisebb az adott érték tárolásigénye a generált indexek is annál kisebbek lesznek.JOIN fajták
A relációs adatbázisok a halmazelméleten alapulnak. Ezt a szakkönyvek szeretik oldalakon keresztül magyarázni. Mint azt, hogy a különböző JOIN-ok hogyan működnek, miközben – ahogy a mondás is tartja – egy kép többet ér ezer szónál.
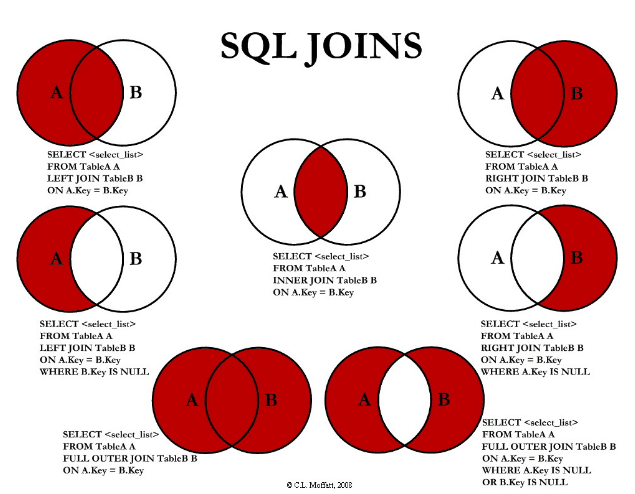
- Optimalizálási szempontból törekedjünk az INNER JOIN használatára, mivel az adja vissza a legkisebb információ halmazt, így az a leggyorsabb. Természetesen nem mindig a metszetre vagyunk kíváncsiak, amikor táblákat kapcsolunk össze, de az esetek nagy részében igen.
- A tábla kapcsolásokat, ha nem körültekintően használjuk, akkor jelentős lassulásokat érhetünk el. Igyekezzünk mindig primary key szerint join-olni vagy olyan mező szerint, ami mindkét táblában fel van indexelve. Ugyanis a táblák közötti kapcsolatot sokkal hamarabb felépíti az adatbázismotor, ha indexelt mezőkkel hivatkozunk a táblákra.
VIEW, avagy a nézettáblák
Tévhit miszerint a VIEW használatával tudunk optimalizálni, mert megspóroljuk a költséges joinolást és a gyakran joinolt táblákat nézettáblákban tároljuk. Ez nem igaz. Nem használhatjuk optimalizálásra. Alapvetően két típusa van a nézettábláknak:- Merge: mindig frissek benne az adatok, használható benne az index, de az adatbázis igazából csak a lekérdezést tárolja, amikor pedig a nézettáblához nyúlunk, akkor lefuttatja.
- Temptable: nekünk kell gondoskodni arról, hogy az adatok frissek legyenek, azaz ha módosítunk az eredeti táblában adatot, akkor azt meg kell tenni a nézettáblában is. Ebben a típusban nem használhatunk indexeket, az adatbázismotor az ilyen nézettáblákat egyfajta előfordított formában tárolja.
Az EXPLAIN használata
Mire jó az EXPLAIN?
A query optimalizálás alapja. Az EXPLAIN tulajdonképpen egy parancs, amit a SELECT elé írva utasítjuk az adatbázismotort, hogy az adott lekérdezést ne hajtsa végre, hanem elemezze azt. Az EXPLAIN segít megérteni, hogy:- Melyek a leglassabb pontok a query-ben.
- Hol tudunk gyorsítani indexek használatával.
- Hogyan épül fel a lekérdezés, hogyan kapcsolódnak a táblák.
- Az egyes kapcsolódások alkalmával hány sort kell feldolgozni.
- Az így kapott elemzés csak egy becslés, de nagyon közel áll a valósághoz.
Az EXPLAIN elemzése
EXPLAIN SELECT * FROMproduct
WHERE price > 5000 AND date_available > ‘2016-01-01’


- select_type: A szelekció típusa. Ebből megtudhatjuk, hogy az adott táblát vagy összetett lekérdezést milyen módon biztosítja nekünk az adatbázismotor.
- table: A tábla neve vagy aliasa.
- type: Az adatelérés típusa. Nagyon fontos információ, a későbbiekben kitérünk rá részletesen.
- possible_keys: Lehetséges kulcsok/indexek, ami közül választhat az adatbázismotor, hogy melyiket használja kereséskor.
- key: Konkrétan az index, amit lekérdezéskor használt a rendszer.
- key_len: A használt index hossza bájtokban.
- ref: Azok a mezők amelyeket JOIN során használ a motor.
- rows: Az átnézett sorok száma. Nagyon fontos információ, ha nem a legfontosabb, ugyanis ez fogja nekünk megmutatni, hogy az adott lekérdezés kiszolgálásához hány sort kellet az adatbázisnak szkennelnie.
- Extra: Különböző extra információk.
Miért fontos az indexek használata?
Az explain segítségével jól szemléltethető az alábbi egyszerű példával hogy miért fontos az indexek használata: EXPLAIN SELECT * FROM product WHERE price > 5000

MySQL optimizer
A MySQL-nek van egy belső optimizere, ami megpróbálja mindig optimális módon visszaadni a keresett rekordokat. Nézzük ezt meg egy újabb lekérdezésben: EXPLAIN SELECT * FROMproduct
WHERE price > 5000 AND date_available > ‘2016-01-01’

Hogyan elemezzük az EXPLAIN-t ?
Igazából az EXPLAIN minden oszlopa hordoz magában információt arról, hogy mi fog történni a lekérdezés során, de két mezőt kiemelhetünk ezek közül. A type és a rows. Valójában a rows a type következménye lesz. A type azt mutatja meg, hogyan érjük el az adatokat. Nyilván ez minél rosszabb, annál nagyobb lesz a rows értékünk, ami egyenesen arányos azzal, hogy maga a lekérdezés is annál lassabb lesz.Type: system, const
- A leggyorsabb type
- A mezőnek unique nem null indexszel kell rendelkeznie
- A SELECT eredménye egyetlen rekord
- Sebességvesztés nélkül tovább join-olható
product WHERE sku = ‘9789639763951’


Type: fulltext
- Leggyorsabb, ha szöveget keresünk
- Nem B-Tree-t használ indexeléshez
- Egyedi szintaktikát kell használnunk



Érdekesség, hogy nyilván több találatunk lesz mint egy, a rows oszlopban mégis egy szerepel. Ennek oka a fulltext indexelés implementálásának a különbsége a többi indextől. Így úgymond nem tudja számolni, de a szövegek keresésének nincs ettől gyorsabb módja.
Type: unique_subquery, index_subquery
- unique_subquery: Index keresés funkció, amely teljesen kicseréli az allekérdezést a hatékonyság érdekében
- index_subquery: Hasonló mint a unique_subquery, de működik nem egyedi indexek esetén is


Szerencsére ettől hatékonyabban van implementálva az egymásba ágyazás. A fenti lekérdezés úgy fog történni, hogy az adatbázismotor észleli, hogy product_id-t keresünk egy olyan halmazban, ami szintén product_id-kat tartalmaz, ami ráadásul egyedi indexszel van ellátva (mivel primary key). Így gyakorlatilag nem fogja minden product_description rekordnál lefuttatni az allekérdezést, hanem behelyettesíti, azaz olyan mintha join-olna subqery helyett. Nyilván így töredéke a futási idő, mivel megspóroljuk az allekérdezést egy join-nal. Ez a funkció viszont csak azokban az esetekben működik, amikor a főlekérdezés egyik egyedi indexszel ellátott mezőjét keressük egy olyan allekérdezésben, aminek az eredménye szintén egyedi indexszel rendelkező mező.
Type: eq_ref, ref, ref_nul
- eq_ref: Táblák kapcsolásakor a legjobb típus, mivel azt jelenti, hogy a kapcsolódás során az első tábla egy adott rekordjához csak egyetlen másik rekord fog kapcsolódni a második táblából.
- ref: Ez már lehet lassú, mivel azt jelenti, hogy táblák kapcsolásakor az első tábla egy adott rekordjához kapcsolódhat több rekord a másik táblából. Eredmény függő, hogy lassú lesz vagy gyors, attól függően, hogy mekkora a számossága az olyan rekordoknak az egyik táblában, amelyhez több rekord kapcsolódhat a másik táblából.
- ref_null: Ugyanaz mint a ref, csak ebben a típusban egyik táblából egy adott rekordhoz a másik táblából nemhogy több rekord kapcsolódhat, hanem még NULL értékek is.
product AS p
LEFT JOIN product_to_category
AS pc ON (p.product_id = pc.product_id)
LEFT JOIN categoryAS c ON (pc.category_id = c.category_id)


Nézzük a lekérdezés elemzését. Előbb végig szkenneljük a teljes product táblát, ez lesz a type all. Aztán minden product rekordhoz hozzákapcsoljuk a product_to_category táblát. Ezen kapcsolódáskor a product tábla egy rekordjához tartozhat több rekord a product_to_category táblából, ezért lesz a kapcsolódás típusa ref. Esetünkben csak hat ilyen rekord van, de láthatjuk, hogy több mint 20000 termékről beszélünk, tehát előfordulhat, hogy 10000 olyan termék lesz, ami több kategóriában is szerepel. Ezért eredmény függő a ref típus, hogy gyors lesz vagy sem. Nézzük tovább. A product_to_category táblához hozzákapcsoljuk category_id szerint a category táblát. Ekkor a kapcsolat típusa eq_ref lesz, mégpedig azért, mert ekkor már ki van választva egy adott product_to_category rekord és egy rekordhoz biztos, hogy csak egyetlen rekord fog kapcsolódni a category táblából.
Itt tegyünk egy kis kitérőt. Az elején azt tárgyaltuk, hogy az INNER JOIN a leggyorsabb tábla kapcsolás. Most vesézzük ki az előző példánál maradva, hogy miért. Nézzük meg ugyanazt a példát, csak most LEFT JOIN helyett használjunk INNER JOIN-t. EXPLAIN SELECT * FROM
product AS p
INNER JOIN product_to_category
AS pc ON (p.product_id = pc.product_id)
INNER JOIN categoryAS c ON (pc.category_id = c.category_id)


Boncoljuk egy kicsit, hogy mi történik ebben az esetben. Először is figyeljük meg a sorrendet: a query-ben a product tábla szerepel előbb, mégis a category táblával kezdünk. A metszet miatt mindegy a táblák kapcsolásának a sorrendje és ezt észleli az optimizer. Az előző explain-ben láthattuk, hogy 20000 termék van, de az optimizer észleli, hogy a kategóriákból csak 106 van és felesleges a 20000 terméket végig szkennelnie. A 3 tábla közül a legkisebbet választja, azaz a kategóriát, mivel az all típus a legköltségesebb ,próbálja azt a legkisebb row értéken tartani. Aztán kapcsolja a product_to_category táblát és legvégül a product táblát. Így pont fordított lesz a táblák sorrendje, mint az előzőekben: a legkisebbektől halad a nagyobbak felé. A kapcsolódási lépcső ennek ellenére ugyanaz marad: all, ref, eq_ref.
Ez az oka annak, hogy az INNER JOIN sokkal gyorsabb, mint az összes többi JOIN. Teret adunk az optimizernek, ami úgy próbálja meg végrehajtani a lekérdezést, hogy az all típusa a legkisebb rekordszámú táblának legyen, tehát ahol végig kell nézni az összes rekordot. Ahol pedig csak egy rekordot kell beazonosítani index alapján, ami nagyon gyors, azaz az eq_ref ilyen típusú legyen a legnagyobb rekordszámú tábla kapcsolata.
Még egy kis kitérő. A rows oszlopban szereplő értékek, azaz hogy hány rekordot kell a becslés szerint szkennelni, átlagosan a processzornak 1 rekord 1 órajelébe kerül. A több táblás rekordokban pedig a rows értékeit össze kell szoroznunk. Hasonlítsuk össze a két példát. Tehát ugyanaz a lekérdezés, de különböző join-t használunk
- LEFT JOIN esetén 20108 X 6 X 1 = 120,648
- INNER JOIN esetén 106 X 343 X 1 = 36,358
Gyakorlatilag az INNER JOIN futási ideje a harmada ebbe az esetben. Több mint 80000 órajelet megspórolunk a processzornak.
Type: range
EXPLAIN SELECT * FROM product WHERE date_available BETWEEN ‘2016-01-01’ AND ‘2016-02-01’


Type: all
A leges legrosszabb típus, kerüljük! Ilyen típusú lesz egy lekérdezés, ha:- nincs WHERE feltételünk
- van WHERE feltétel, de az nincs indexelve, ezért nagyon fontos az indexelés
- túl sok rekord felel meg a WHERE feltételnek, ekkor az index is hiába
product WHERE price BETWEEN 1 AND 100000

Láthatjuk a példában, hogy hiába szerepel indexelt mező a WHERE feltételben, akkora az intervallum, amit le akarunk kérni, hogy full table scan lesz a vége. Azaz a tábla összes rekordját vizsgálni kell, legyen abban akárhány rekord.
EXPLAIN Type-ok összegzése
- System, const, fulltext, index_subquery, unique_subquery, eq_ref: Semmi teendőnk, jó eséllyel optimális a query-nk.
- Ref, ref_nul: Elgondolkodhatunk némi optimalizáláson, hogy nem tudjuk-e másként lekérni az adatokat.
- Range: Vagy gondolkodjunk el SQL optimalizáláson vagy győződjünk meg róla, hogy az adott queryben használt intervallumba nem fog nagyobb rekordszám esni.
- ALL: A legrosszabb típus. Mielőbb írjuk át, ha ilyen query-vel találkozunk. Biztos fogunk. Ha mást nem optimalizálunk, csak arra törekszünk, hogy all típus egyik query-nkben sem legyen, már rengeteget tettünk egy gyorsabb weboldalért és a kisebb szerver terheltségért. Ha az egész cikkből ennyit hasznosítunk, hogy nézzük meg explain-nel a query-nket és írjuk át ha ALL szerepel benne, akkor már nyertünk.
EXPLAIN Extra oszlopa
Végezetül ejtsünk pár szót az extra oszlopról, a legfontosabbak:
- Using where: Arra utal, hogy a WHERE feltételünkben szerepel olyan mező, ami nincs indexelve.
- Using temporary table: Olyan tábla kapcsolást vagy egymásba ágyazást használunk, amihez ideiglenesen cache táblát kell létrehozni az adatbázismotornak. Ez nyilván nem optimális.
- Using filesort: A leggyakrabban akkor láthatunk ilyet, ha ORDER BY-t használunk. Ami nagyon népszerű viszont kevesen tudják, hogy ekkor az adatbázis nem tudja használni az indexet, a rendezéshez plusz fájlműveleteket használ, ami nagyon lassú. Minél nagyobb rekordszámot rendezünk, annál lassabb, ezért érdemes csak kevés rekordra alkalmazni.
Amikor az SQL optimalizáció már nem elég
Vannak speciális feladatok, amikor a MySQL nem jó választás. Ilyen például a szabad szavas kereső (keresés termék névben, leírásban, stb.). A relációs adatbázisokat nem kifejezetten ilyen keresésre alkották. Kisebb projekteknél természetesen nem kell külön keresési technológiákban gondolkodnunk. Értjük ezalatt a maximum pár ezer rekordban való keresést minimális és egyszerű szűrési feltételek mellett. Azonban nagyobb projekteknél elérjük azt a pontot, amikor már bonyolult feltételek mellett, több olyan táblát kell kapcsolnunk vagy egymásba ágyaznunk, amelyek több tízezer rekordot tartalmaznak.
A rengeteg kapcsolat és sok szűrési feltétel miatt egyszerűen ezeket már nem lehet optimalizálni. Ami abból adódik, hogy a relációs adatbázisokat nem erre tervezték. Nem tud egy adott táblán egynél több index alapján keresni és nem tud egy adott query-t külön szálakon futtatni. Tehát legyen egy akárhány magos processzorunk a MySQL szerverünk alatt, egy query-hez csak egy magot fog használni. Ezen a ponton már akár másodpercekben mérhető az adatbázis válaszideje. Ez felhasználói szempontból egyszerűen élményromboló. Ezen a ponton el kell gondolkoznunk új adatbázis (pl ElasticSearch) használatán. De ez már egy másik cikk témája.
Összegzés
- Legyünk tisztában az adatbázis működésével. Értsük, hogy az egyes műveletek mögött mi történik pontosan.
- Használjunk inkább több indexet, mint kevesebbet. Törekedjünk arra, hogy a szoftverünk minél kevesebb írási műveletet használjon.
- Használjuk az EXPLAIN parancsot, az optimalizálás alapja. A legfontosabb, hogy ha ALL típust látunk valamely elemzés során, igyekezzünk átírni a query-nket.